Anyscale
Contents
Anyscale#
Fugue works perfectly well with Anyscale. This document assumes you already have an Anyscale account setup and you know the basic operations on Anyscale. You can sign up Anyscale here.
Create Fugue environment#
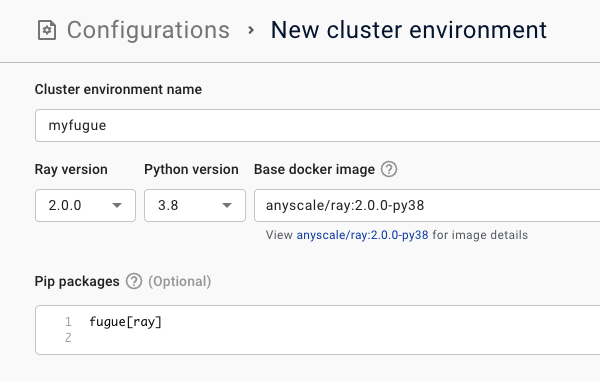
You must create a new compute environment on Anyscale where you must
Install
fugue[ray]Make sure ray>=2.0.0
It’s recommended to use python 3.8+
Besides that, if you want to use s3, please install fs-s3fs, if you want to use gcs, please install fs-gsfs.
Start from the jupyter notebook inside Anyscale#
The easiest way to start trying is to start a cluster inside Anyscale, and then use the jupyter notebook
Using this approach, you only need to use the standard Ray execution engine, for example:
transform(df, func, engine="ray")
Start from your local enrionment#
Firstly, please pip install on your local environment:
pip install fugue-cloudprovider[anyscale]
You need to get your token in Anyscale:
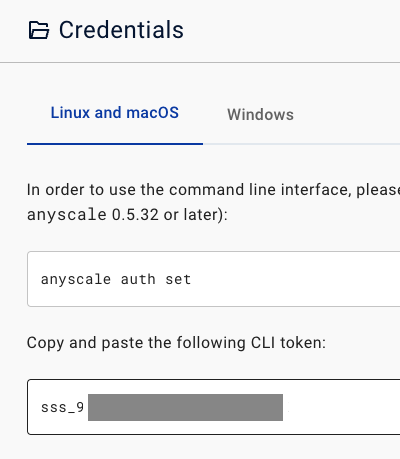
You can choose to use the command to login:
anyscale auth set
Or, you can add token to your engine config (will have more examples later):
{
"token": "..."
}
Putting explicit token in engine config is not a good practice. But if your config is stored at a secret store, it can be both safe and convenient.
Engine configs#
Config items:#
token
The Anyscale token for authentication, it is required if you have not logged in on your machine
address
The anyscale://... address representing a predefined cluster:
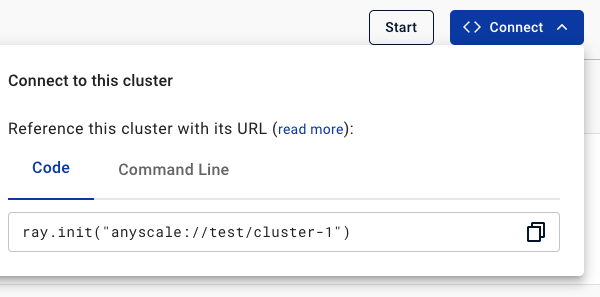
One and only one of address and cluster must be specified
cluster
The parameter to launch a cluster. You can use this option to construct a new cluster on the fly.
ephemeral (default: False)
Whether to terminate this Anyscale cluster when the Fugue execution engine is shutdown.
fugue.ray.shuffle.partitions
Default number of shuffle partitions when groupby and transform. If not set, it will be determined by the number of partitions of the input dataframe.
Notice for Anyscale, if this config is not set, and if the max number of cpus (cpu_n) of the cluster can be computed,
then this config will be automatically set to cpu_n * 2
fugue.ray.remote.*
Default ray remote arguments used by Fugue
RayExecutionEngine. For example:
transform(
...,
engine="anyscale://project/cluster-1",
engine_conf={
"fugue.ray.remote.num_cpus":2
}
)
Each transformation task will take 2 cpus. If you have a Ray cluster of 100 cpus, then the max parallelism will be 50.
Config combinations:#
engine="anyscale", engine_conf={...}
This is the most standard way, for example:
transform(..., engine="anyscale", engine_conf={"token":"...", "cluster":{...}, "ephemeral":True})
engine="<anyscale address>", engine_conf={...}
This is equivalent to engine="anyscale", engine_conf={"address":"<anyscale address>", ...}.
The simplest example would be (assuming you logged in Anyscale on the machine):
transform(..., engine="anyscale://project/cluster-1")
It will connect to the remote predefined cluster (if the cluster is not started, then it will launch the cluster first and then connect)
The programmatical approach
In fugue-cloudprovider we provided a utility class Cluster to connect/create remote Anyscale clusters.
All engine configs will also work for the Cluster class:
from fugue_anyscale import Cluster
with Cluster({"address":"anyscale://project/cluster-1", "ephemeral":True}) as cluster:
transform(..., engine=cluster)