Using Fugue on Databricks
Contents
Using Fugue on Databricks#
A lot of Spark users use the databricks-connect library to execute Spark commands on a Databricks cluster instead of a local session. databricks-connect replaces the local installation of pyspark and makes pyspark code get executed on the cluster, allowing users to use the cluster directly from their local machine.
In this tutorial, we will go through the following steps:
Setting up a Databricks cluster
Installing and configuring
databricks-connectUsing Fugue with a Spark backend
Setup Workspace#
Databricks is available across all three major cloud providers (AWS, Azure, GCP). In general, it will involve going to the Marketplace of your cloud vendor, and then signing up for Databricks.
For more information, you can look at the following cloud-specific documentation.
https://databricks.com/product/aws
https://databricks.com/product/azure
https://databricks.com/product/google-cloud
The picture below is what entering a workspace will look like
Create a Cluster#
From here, you can create a cluster by clicking the “New Cluster” link. The cluster will serve as the backend for our Spark commands. With the databricks-connectpackage that we will use later, we can connect our laptop to the cluster automatically just by using Spark commands. The computation graph is built locally and then sent to the cluster for execution.
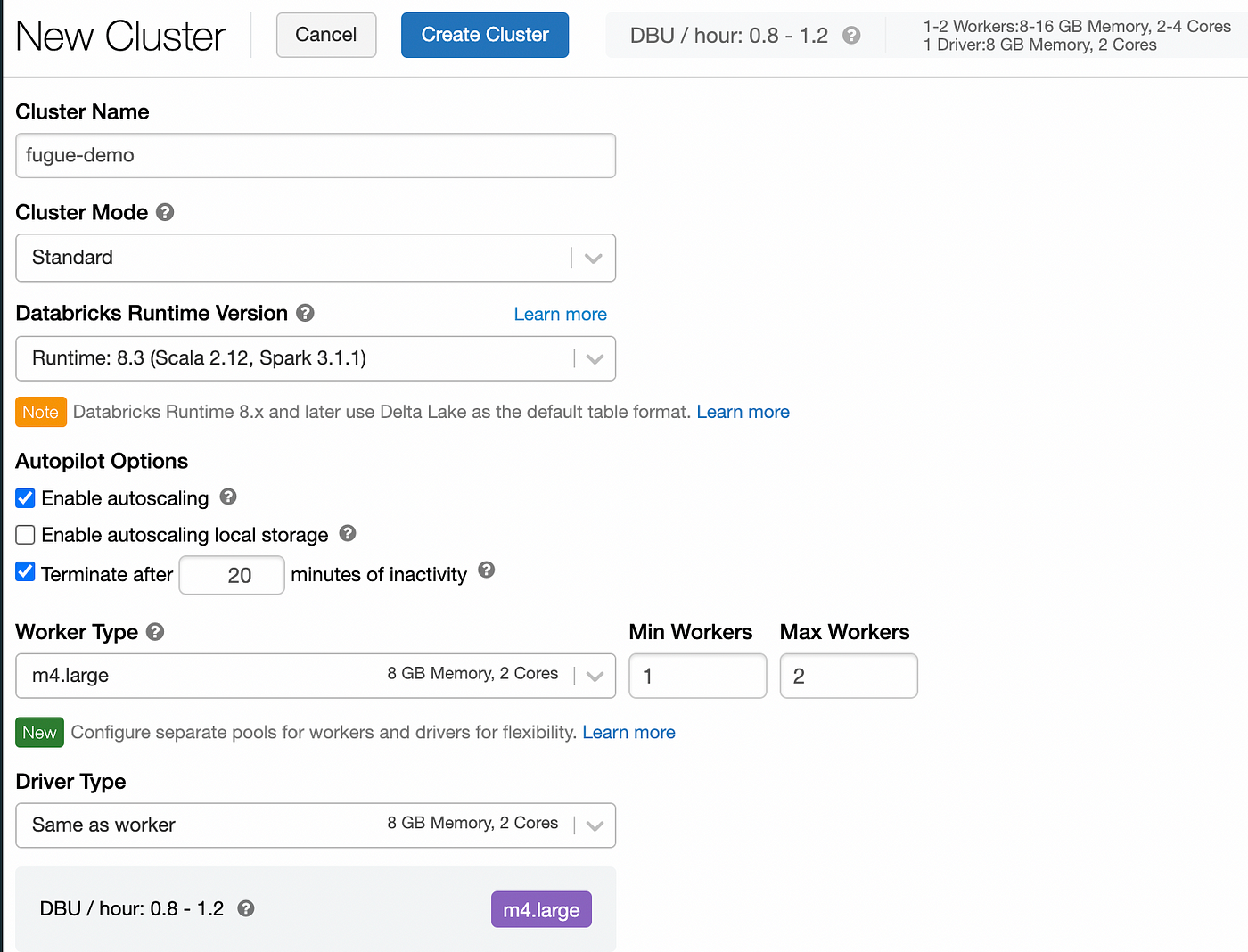
Note when creating a cluster that you can start out by reducing the Worker Type. Clusters can be very expensive! Be sure to lower the worker type to something reasonable for your workload. Also, you can enable autoscaling and terminating the cluster after a certain number of minutes of inactivity.
Installing Fugue#
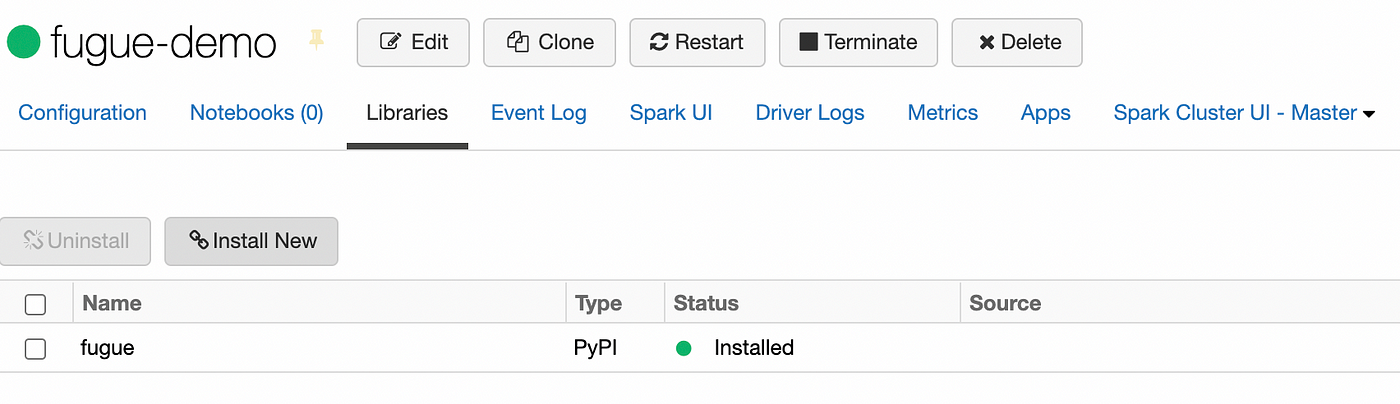
In order to use Fugue on the cluster from our local environment, we need to install it on the cluster that we created. The easiest way to do this is to navigate the the libraries tab and add the package there. Below is an image of the tab.
Databricks-connect#
databricks-connect is a library that Databricks provides to run Spark commands on the cluster. The content here will just be a summary, but the full guide to installing databricks-connect can be found here.
databricks-connect can be installed using pip:
pip uninstall pyspark
pip install databricks-connect
Pyspark needs to be uninstalled because it conflicts with databricks-connect. databricks-connect will replace your pyspark installation. This means that import pyspark will load the databricks-connect version of PySpark and all succeeding Spark commands are sent to the cluster for execution.
Note that the version of databricks-connect must match the Databricks Runtime Version of your cluster. Otherwise, you will run into errors and the code will not be able to execute correctly.
Configuring the Cluster#
Now that you have a cluster created from the first step and databricks-connect installed, you can configure the cluster by doing databricks-connect configure.
There are more details where to get the relevant pieces of information in their documentation here. For my example on AWS, it looked like this:

You can verify if this worked by using databricks-connect test, and then you should see a message that all tests passed.
Fugue and databricks-connect#
After setting the cluster up and configuring databricks-connect to point to the cluster, there is no added effort needed to connect Fugue to your Spark cluster. The SparkExecutionEngine imports pyspark, meaning that it will import the databricks-connect configuration under the hood and use the configured cluster. Fugue works with databricks-connect seamlessly, allowing for convenient switching between local development and a remote cluster.
The code below will execute on the Databricks cluster if you followed the steps above. In order to run this locally, simple use the default NativeExecutionEngine instead of the SparkExecutionEngine
import pandas as pd
from fugue import transform
from fugue_spark import SparkExecutionEngine
data = pd.DataFrame({'numbers':[1,2,3,4], 'words':['hello','world','apple','banana']})
# schema: *, reversed:str
def reverse_word(df: pd.DataFrame) -> pd.DataFrame:
df['reversed'] = df['words'].apply(lambda x: x[::-1])
return df
spark_df = transform(data, reverse_word, engine=SparkExecutionEngine())
spark_df.show()
+-------+------+--------+
|numbers| words|reversed|
+-------+------+--------+
| 1| hello| olleh|
| 2| world| dlrow|
| 3| apple| elppa|
| 4|banana| ananab|
+-------+------+--------+
Additional Configuration#
Most databricks-connect users add additional Spark configurations on the cluster through the DAtabricks UI. If additional configuration is needed, it can be provided with the following syntax:
from pyspark.sql import SparkSession
from fugue_spark import SparkExecutionEngine
spark_session = (SparkSession
.builder
.config("spark.executor.cores",4)
.config("fugue.dummy","dummy")
.getOrCreate())
engine = SparkExecutionEngine(spark_session, {"additional_conf":"abc"})
Using Fugue-sql on the Cluster#
Because Fugue-sql also just uses the SparkExecutionEngine, it can also be easily executed on a remote cluster.
from fugue_notebook import setup
setup()
%%fsql spark
SELECT *
FROM data
TRANSFORM USING reverse_word
PRINT
| numbers | words | reversed | |
|---|---|---|---|
| 0 | 1 | hello | olleh |
| 1 | 2 | world | dlrow |
| 2 | 3 | apple | elppa |
| 3 | 4 | banana | ananab |
Conclusion#
Here we have shown how to connect Fugue to a Databricks cluster. Using Fugue along with databricks-connect provides the best of both worlds, only utilizing the cluster when needed.
databricks-connect can slow down developer productitity and increase compute costs because all the Spark code becomes configured to run on the cluster. Using Fugue, we can toggle between Fugue’s default NativeExecutionEngine and SparkExecutionEngine. The default NativeExecutionEngine will run on local without using Spark and Fugue’s SparkExecutionEngine will seamlessly use whatever pyspark is configured for the user.
Fugue also allows for additional configuration of the underlying frameworks. We showed the syntax for passing a SparkSession to the SparkExecutionEngine.